
 English
English  한국어
한국어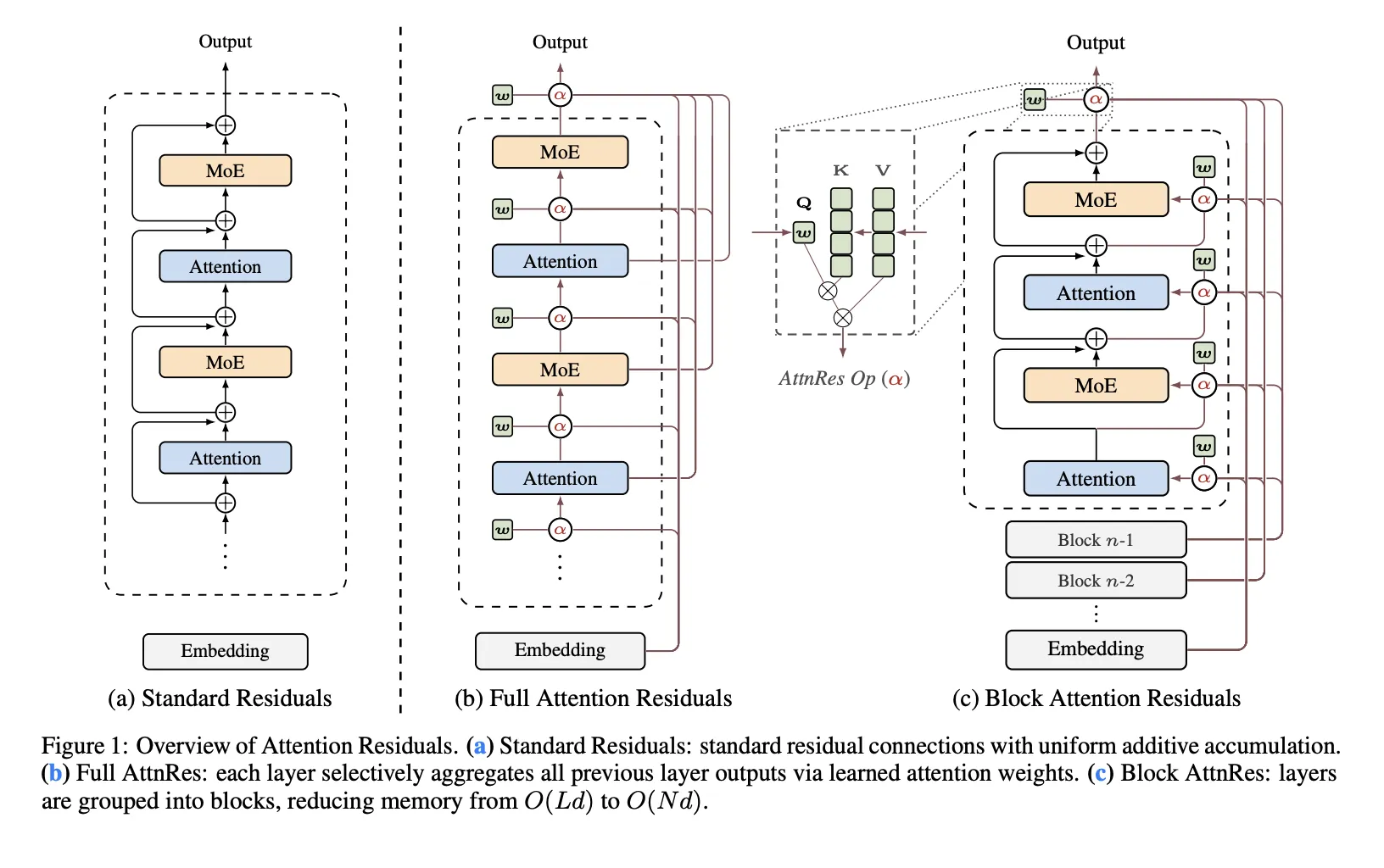
## Transformer Models are Hitting Performance Limits? Attention Residuals Offer a Solution! 😎
Over the past few years, transformer models have achieved tremendous success in the field of natural language processing. However, some problems arose as models became deeper. In particular, the standard residual connection method made the optimization process unstable and acted as a limiting factor in model performance. Moonshot AI researchers have proposed a groundbreaking solution to these problems, namely **Attention Residuals**.
Attention residuals are based on a simple yet powerful idea. Instead of the conventional fixed residual connection method, this method uses softmax attention to weight and aggregate the representation of the previous layer for each layer. This innovation significantly improves model performance and enables better scaling. In this article, we will explore the workings, advantages, and impact on the industry of attention residuals in detail. Are you ready? 🚀
### 1. Why Do Existing Residual Connection Methods Cause Bottlenecks?
The existing residual connection method may seem simple, but it has some problems. The research team pointed out these problems as follows:
* **Inability of Selective Access:** Because all layers aggregate information in the same way, it is difficult to selectively utilize only the information needed for a specific layer.
* **Irreversible Information Loss:** Once aggregated, information is difficult to recover.
* **Output Increase:** Deeper layers must generate larger outputs to maintain influence, which can destabilize training.
These problems acted as limiting factors for transformer model performance. However, **attention residuals** are a powerful solution to solve these problems and elevate model performance one step further.
### 2. How Do Attention Residuals (AttnRes) Work?
**Attention residuals** completely replace the existing residual connection method. Each layer performs softmax attention on the output of the previous layer to calculate weights and aggregates information based on them. This method allows for selective use of previous layer representations based on input data, minimizes information loss, and solves the output increase problem.
Moonshot AI researchers proposed two versions: Full AttnRes and Block AttnRes. Full AttnRes performs attention on all previous layers, but has the disadvantage of high computational cost. Block AttnRes divides layers into several blocks and performs attention on a block-by-block basis to reduce computational cost. This method is more suitable for application to large-scale models and provides the efficiency needed for actual use. Attention residuals play an important role in effectively managing model complexity while improving performance, just like this.
### 3. How Much Performance Improvement Can Be Expected with Attention Residuals?
Moonshot AI researchers evaluated the performance of attention residuals in various model sizes. As a result, **attention residuals** achieved lower validation loss compared to the conventional method, and Block AttnRes achieved the same performance as training with approximately 1.25 times more computational resources. In addition, by integrating attention residuals into a MoE (Mixture of Experts) architecture called Kimi Linear and training, it was confirmed that performance improved in various benchmarks such as inference, coding, and evaluation. In particular, **attention residuals** contributed to limiting the output size of the model, increasing training stability, and distributing gradients evenly layer by layer. **Attention residuals** play an important role not only in improving performance but also in increasing the stability and efficiency of the model.
### Attention Residuals, a Key Technology to Transform the Future of Transformer Models! 🌟
**Attention residuals** from Moonshot AI are an innovative technology that improves the performance of transformer models and enables better scaling. This technology can be used in various fields such as natural language processing, computer vision, and speech recognition, and is expected to contribute significantly to the advancement of artificial intelligence technology. It is expected that new models based on **attention residuals** will appear in the future, and more powerful and efficient artificial intelligence systems will be built.
## Technical Implications
* **Utilization of Attention Mechanisms:** Attention mechanisms can be extended in depth to control information flow within the network.
* **Reinterpretation of Residual Connections:** Residual connections can be reinterpreted as selective information combination through attention, rather than simple information aggregation.
* **Improvement of Computational Efficiency:** Computational complexity can be reduced by using Block AttnRes, making it easier to apply to large-scale models.
* **Stabilization of PreNorm Models:** Attention residuals can improve the training stability and performance of PreNorm models.
* **Optimization of MoE Architectures:** Dilution problems in MoE architectures can be alleviated and the performance of each expert model can be maximized.
In-depth Analysis and Implications
– Utilization of Attention Mechanisms: Attention mechanisms can be extended in depth to control information flow within the network.
– Reinterpretation of Residual Connections: Residual connections can be reinterpreted as selective information combination through attention, rather than simple information aggregation.
– Improvement of Computational Efficiency: Computational complexity can be reduced by using Block AttnRes, making it easier to apply to large-scale models.
– Stabilization of PreNorm Models: Attention residuals can improve the training stability and performance of PreNorm models.
– Optimization of MoE Architectures: Dilution problems in MoE architectures can be alleviated and the performance of each expert model can be maximized.
Original Source: Moonshot AI Releases 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔 to Replace Fixed Residual Mixing with Depth-Wise Attention for Better Scaling in Transformers