
 English
English  한국어
한국어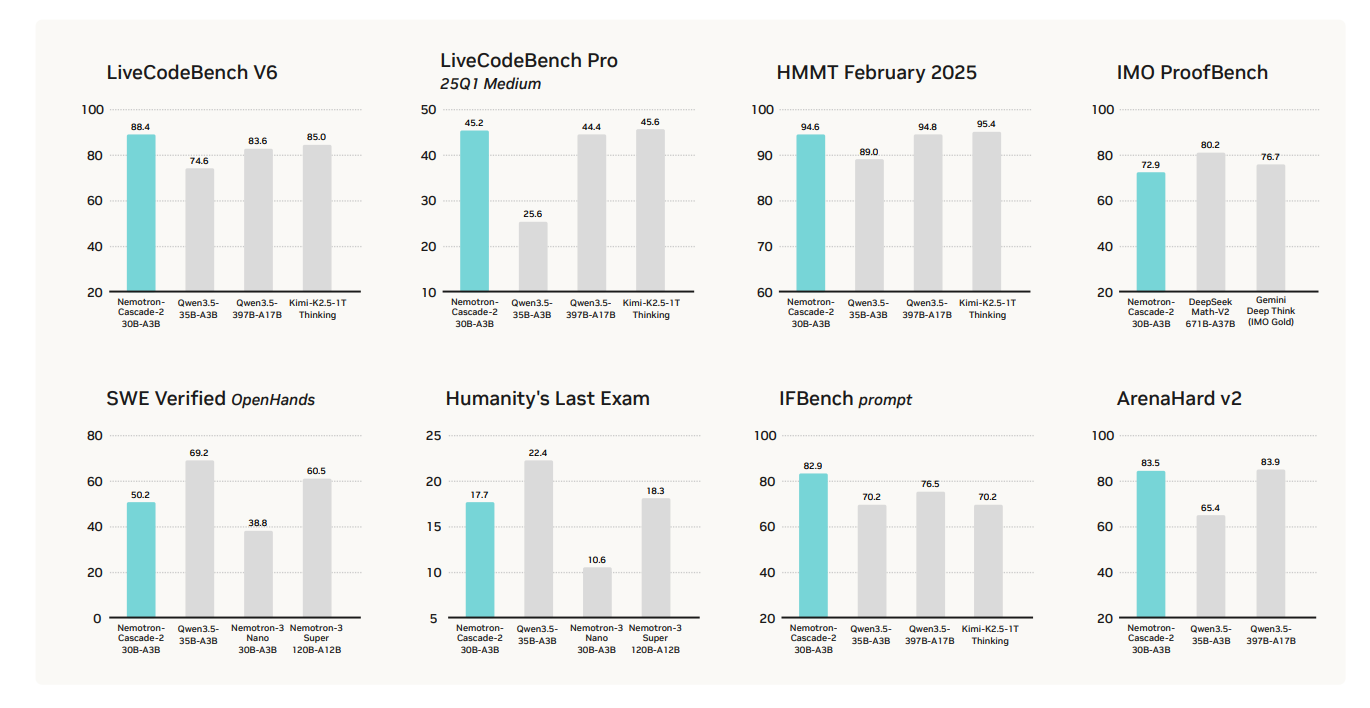
NVIDIA Nemotron-Cascade 2: Open-Source 30B MoE Model Launches with Enhanced Reasoning and Powerful Agent Capabilities
Innovation in the field of artificial intelligence continuously amazes us. Large language models (LLMs), in particular, have demonstrated remarkable achievements in various areas such as natural language processing, text generation, and code generation. In line with this trend, NVIDIA has opened up a new horizon for LLM development by releasing a new open-source model, Nemotron-Cascade 2. Nemotron-Cascade 2 moves away from the massive scale of existing models, focusing on maximizing efficiency and performance through a new concept called ‘intelligence density’.
The emergence of Nemotron-Cascade 2 represents not just the release of a new LLM, but also a significant turning point in the direction of AI research and development. Traditional large-scale models require enormous computing resources and energy, which entails various challenges such as increased research and development costs and environmental problems. Nemotron-Cascade 2 aims to solve these problems and contribute to exploring new possibilities for more efficient and sustainable AI technology development.
Nemotron-Cascade 2: Key Features and Performance
Nemotron-Cascade 2 is a 30 billion parameter Mixture-of-Experts (MoE) model. Its key feature is that it is designed to maximize ‘intelligence density’. This means increasing efficiency by activating only the parameters needed for specific tasks, rather than activating all parameters. It demonstrates outstanding performance in specific areas such as mathematical reasoning, coding, alignment, and instruction following, outperforming existing models in these fields.
Mathematical Reasoning Ability: Overwhelming Performance that Surpasses Existing Models
Nemotron-Cascade 2 particularly demonstrates outstanding mathematical reasoning ability. It achieved high scores, surpassing the existing Qwen3.5-35B-A3B model in mathematical competitions such as AIME 2025 and HMMT Feb25. This proves that Nemotron-Cascade 2 has undergone specialized training for mathematical problem-solving. The improvement in Nemotron’s mathematical reasoning ability is expected to have a positive impact on the development of AI-based education systems and mathematical research fields.
Coding Ability: Remarkable Growth in LiveCodeBench v6 and IOI 2025
Nemotron-Cascade 2 also demonstrates excellent coding ability. It achieved results significantly surpassing existing models in coding benchmarks such as LiveCodeBench v6 and IOI 2025. This means that the Nemotron model possesses efficient code generation and debugging capabilities, contributing to improved software development productivity and the construction of automated coding systems.
Alignment and Instruction Following: High Scores in ArenaHard v2 and IFBench
Nemotron-Cascade 2 also shows excellent results in text alignment and instruction following. It achieved higher scores than existing models in benchmarks such as ArenaHard v2 and IFBench, demonstrating the ability to accurately understand user intentions and generate appropriate responses. The Nemotron model’s capabilities in this area can be utilized in various fields such as chatbots, virtual assistants, and content creation.
Technical Architecture: Innovative Combination of Cascade RL and MOPD
Nemotron-Cascade 2’s outstanding performance is achieved not simply by increasing model size, but through an innovative technical architecture. The model was trained through three main stages: Supervised Fine-Tuning (SFT), Cascade Reinforcement Learning (RL), and Multi-Domain On-Policy Distillation (MOPD).
In the SFT stage, a vast dataset with a maximum token length of 256K was utilized to improve the model’s basic capabilities. Subsequently, Cascade RL was used to proceed with domain-specific training optimized for mathematics, coding, and software engineering. In particular, MOPD maximized learning efficiency by utilizing a ‘teacher model’ and enabled the achievement of high performance even with less data. This technical innovation of Nemotron has the potential to shift the paradigm of LLM development.
Inference Features and Agent Interaction
Nemotron-Cascade 2 supports two main operating modes according to user needs: ‘Thinking Mode’ activates in-depth reasoning required for complex mathematical and coding tasks, while ‘Non-Thinking Mode’ provides more efficient direct responses. In addition, in agent-based tasks, a structured tool-calling protocol is used to facilitate interaction between the user and the model. These features support users in utilizing the Nemotron model more efficiently.
Future Outlook and Industry Impact
The emergence of Nemotron-Cascade 2 is presenting a new direction for LLM research and development. It emphasizes the importance of maximizing ‘intelligence density’ and developing models optimized for specific domains, moving away from a focus on large models. This can contribute to reducing AI technology development costs and solving environmental problems, and is expected to broaden the possibilities for AI technology utilization in various fields.
The open-source release of the Nemotron model will have a positive impact on the AI community. Researchers can conduct new research based on Nemotron-Cascade 2 and apply it to various fields. In addition, companies can develop their own AI solutions utilizing the Nemotron model and strengthen their competitiveness. Nemotron will democratize AI technology and contribute to enabling more people to benefit from AI technology.
Technical Insight
- Utilization of MoE Architecture: The Mixture-of-Experts (MoE) architecture was utilized to maximize intelligence density and increase the model’s efficiency.
- Cascade RL: Domain-specific training through sequential learning improves performance in specific areas and prevents catastrophic forgetting.
- MOPD: Multi-Domain On-Policy Distillation improves learning efficiency and leverages the strengths of the teacher model to improve performance.
- Tool-Calling Protocol: A structured tool-calling protocol is used in agent-based tasks to facilitate interaction between the user and the model.
- Optimization for Specific Domains: Demonstrates outstanding performance in specific areas such as mathematics, coding, alignment, and instruction following, providing specialized problem-solving capabilities.
In-Depth Analysis and Implications
- Utilization of MoE Architecture: The Mixture-of-Experts (MoE) architecture was utilized to maximize intelligence density and increase the model’s efficiency.
- Cascade RL: Domain-specific training through sequential learning improves performance in specific areas and prevents catastrophic forgetting.
- MOPD: Multi-Domain On-Policy Distillation improves learning efficiency and leverages the strengths of the teacher model to improve performance.
- Tool-Calling Protocol: A structured tool-calling protocol is used in agent-based tasks to facilitate interaction between the user and the model.
- Optimization for Specific Domains: Demonstrates outstanding performance in specific areas such as mathematics, coding, alignment, and instruction following, providing specialized problem-solving capabilities.


