
 English
English  한국어
한국어 日本語
日本語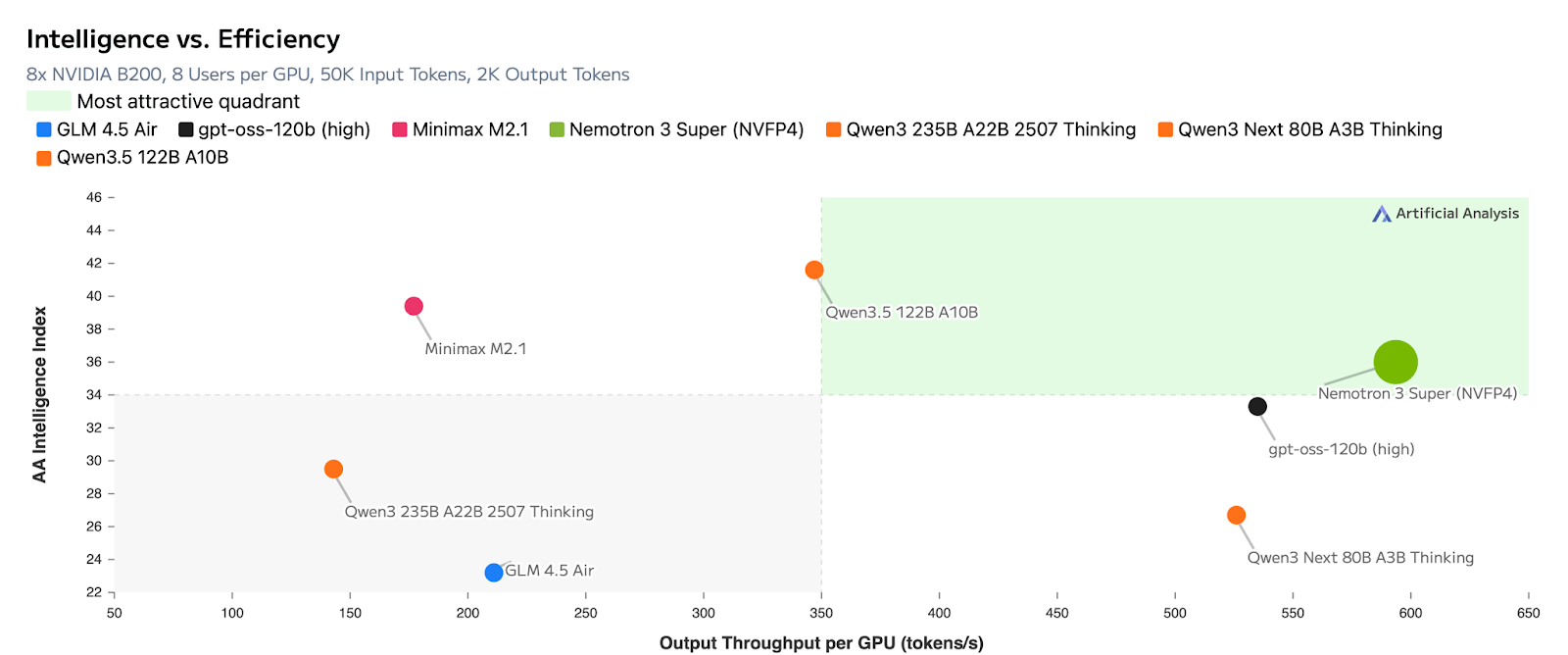
The gap between closed (proprietary) large language models and transparent open-source models is rapidly shrinking. NVIDIA’s recently released Nemotron 3 Super is a prime example of this shift. This model consists of 120 billion parameters and is specifically designed for complex multi-agent applications. The arrival of Nemotron 3 Super is opening a new era in AI model development.
With Nemotron 3 Super, NVIDIA has dramatically improved the performance, efficiency, and accessibility of AI models. This model sits between the lightweight 30 billion parameter model, Nemotron 3 Nano, and the 50 billion parameter model, Nemotron 3 Ultra, offering up to 7 times higher throughput and twice the accuracy compared to previous generations. Nemotron 3 Super empowers developers to build innovative applications without having to compromise between performance and efficiency.
Nemotron 3 Super’s Innovation: 5 Key Technologies
Nemotron 3 Super’s exceptional performance is backed by five major technological innovations. These innovations maximize the model’s efficiency and accuracy, creating an environment suitable for multi-agent AI systems.
- Hybrid MoE Architecture: This model intelligently combines memory-efficient Mamba layers with high-precision Transformer layers. It activates only a portion of the parameters when generating each token, improving KV and SSM cache utilization efficiency by a factor of 4.
- Multi-Token Prediction (MTP): The model predicts multiple future tokens simultaneously, providing up to 3 times faster inference time in complex reasoning tasks. This is a key factor enabling the speed of Nemotron models.
- 1 Million Context Window: Boasting 7 times larger context length than previous generations, developers can now put large volumes of technical reports or entire codebases directly into the model’s memory. This eliminates the need for re-inference in multi-step workflows.
- Sparse MoE: This technology compresses information and allows four experts to be activated at the same computing cost. Without this innovation, the model would have to be 35 times larger to achieve the same accuracy.
- NeMo RL Gym Integration: The model learns through an interactive reinforcement learning pipeline, not only on static text but also through dynamic feedback loops. This effectively doubles the intelligence quotient (IQ).
The Ultimate Engine for Multi-Agent AI, Nemotron 3 Super
Nemotron 3 Super is not just a large language model, but a reasoning engine designed to plan, validate, and execute complex tasks within a system of specialized models. This architecture will revolutionize multi-agent workflows.
- High Throughput for Deep Reasoning: The model’s 7 times higher throughput physically expands the exploration space. The ability to process and generate more tokens quickly allows for the exploration of more paths and the evaluation of better responses.
- Preventing Re-inference in Long Workflows: In multi-agent systems, agents are constantly passing context back and forth. With a 1 million token context window, the model can keep extensive states, such as an entire codebase or a long multi-step agent dialogue history, directly in memory.
- Agent-Specific Training Environments: The model pipeline extends beyond reliance on static text datasets to include 15+ interactive reinforcement learning environments.
- Advanced Tool Calling Capabilities: In real-world multi-agent applications, models must not only respond in text but also take action. Nemotron 3 Super has already demonstrated powerful tool calling capabilities upon release.
Open Source & Training Scale
NVIDIA has gone beyond simply releasing model weights by also opening up the entire model stack, including the training dataset, libraries, and reinforcement learning environments. This transparency is the basis for Artificial Analysis’s assessment that Nemotron 3 Super falls into the most attractive quadrant. The model’s intelligence is built upon a dataset of 10 trillion curated tokens, with an additional 90-100 billion tokens for advanced coding and reasoning tasks. This is a core competitive advantage of the Nemotron model.
Developer Control: Introducing ‘Inference Budget’
While the raw parameter count and benchmark scores are impressive, real-world enterprise developers need precise control over latency, user experience, and computing costs. NVIDIA has introduced an innovative feature called the ‘inference budget’ to resolve the classic dilemma between intelligence and speed. Developers can now dynamically adjust the model’s ‘thinking’ level for specific tasks, allowing Nemotron models to allocate the exact computing resources needed to provide users with the optimal response.
Real-World Applications & Availability
Nemotron 3 Super is already demonstrating exceptional performance in diverse fields such as software development, cybersecurity, and sovereign AI. It is particularly being leveraged to build models tailored to specific regions and regulatory frameworks, such as India, Vietnam, Korea, and Europe.
Nemotron 3 Super supports BF16, FP8, and NVFP4 quantization methods, and requires NVFP4 to run on DGX Spark. You can find the model on Hugging Face and learn more in the research paper and technical/developer blogs.
In-Depth Analysis & Implications
Array
Original Source: NVIDIA Releases Nemotron 3 Super: A 120B Parameter Open-Source Hybrid Mamba-Attention MoE Model Delivering 5x Higher Throughput for Agentic AI