
 English
English  한국어
한국어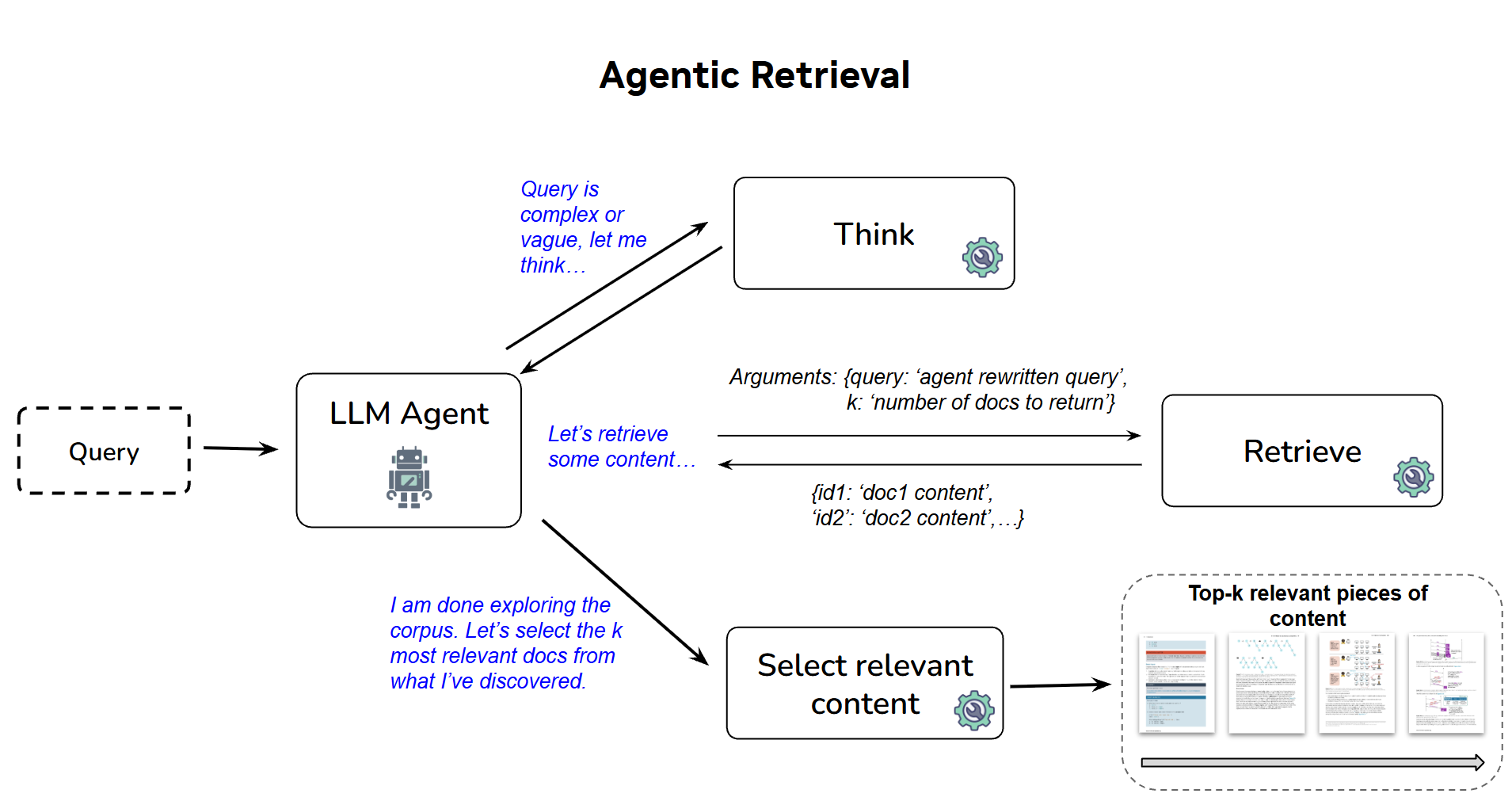
Introducing NVIDIA NeMo Retriever: A Generalizable Agentic Retrieval Pipeline
The field of AI search is rapidly evolving, with many solutions excelling at specific tasks. However, in real-world enterprise environments, data is often imperfect, and a variety of problems can arise. Systems must be able to seamlessly handle diverse challenges, such as complex visual layout analysis and in-depth logical reasoning. NVIDIA NeMo Retriever was developed to meet these requirements.
NeMo Retriever is designed with a focus on generalizability. Instead of relying on task-specific heuristics, it dynamically adjusts search and reasoning strategies based on the data through an agentic retrieval pipeline. This allows it to achieve state-of-the-art performance across various benchmarks while maintaining a robust foundation architecture. That is, agentic retrieval technology plays a crucial role in meeting a wide range of enterprise information retrieval needs.
The Motivation: Why Semantic Similarity Isn’t Enough
For years, dense retrieval based on semantic similarity has been the standard for information retrieval. However, as search applications have grown, finding relevant documents is often not sufficient with simple semantic similarity. Complex document searches require reasoning abilities, understanding of real-world systems, and iterative exploration. LLMs excel at reasoning, but cannot process millions of documents at once, while search systems can easily search millions of documents, but have limited reasoning capabilities. Agentic retrieval helps bridge this gap between LLMs and search systems.
How It Works: The Agentic Loop
The agentic retrieval pipeline in NeMo Retriever is based on the ReACT architecture. Instead of ‘finishing’ with a single query, agents iteratively search, evaluate, and refine their approach. The agent uses a ‘think’ tool to plan an approach and a ‘final_results’ tool to output the specific documents needed for a given query. It also uses a ‘retrieve(query, top_k)’ tool to explore the corpus. Through these loops, successful search patterns emerge naturally:
- Better query generation: Agents dynamically adjust search queries based on newly discovered information.
- Continuous rephrasing: Continuously rephrase queries until useful information is found.
- Complexity decomposition: Break down complex, multi-part queries into multiple simpler queries with clear goals.
Through this process, the agent outputs the most relevant documents and scores documents based on relevance to the given query. When a maximum number of steps or a context length limit is reached, or when the agent loses autonomy, it transitions to Reciprocal Rank Fusion (RRF) – scoring documents based on their rank across all search attempts.
Engineering for Speed and Scale
An agentic retrieval workflow is generally slower and more resource-intensive. Therefore, to make this pipeline viable for leaderboard-scale evaluations, we needed to reconsider how LLM agents and search systems communicate. Initially, the search system was exposed through a Model Context Protocol (MCP) server, but MCP proved to be a bottleneck in experimental speed. To address this, we replaced the MCP server with a thread-safe singleton search system within the process. This singleton search system loads the model and corpus embeddings once, protects access with re-entrant locks, and exposes the same ‘retrieve()’ interface to a virtually unlimited number of concurrent agent tasks. This single architectural change significantly reduced the scope of deployment errors and dramatically improved GPU utilization and experiment throughput.
Generalization vs. Specialization Across Benchmarks
A common observation in modern search evaluation is that solutions optimized for a specific task often perform poorly when applied to completely different domains. The agentic retrieval in NeMo Retriever is designed to address this issue. Instead of relying on heuristics for a specific dataset, the agent loop naturally adapts strategies based on the data.
Ablation Studies: Open vs. Closed Models
The NeMo Retriever team analyzed agentic retrieval performance using various models. Comparing open-source models with commercial models helped identify the optimal combinations and evaluate their impact on performance, providing valuable insights for developing solutions to meet a wide range of enterprise requirements.
The Cost of Autonomy and What’s Next
Agentic retrieval is more expensive and slower than standard dense retrieval. However, the NeMo Retriever team believes that agentic retrieval is a highly valuable approach for high-stakes losses and complex queries. The team is currently focusing on cost reduction and researching how to distill agent reasoning patterns into smaller, specialized open-source agents.
Build Your Own Agentic Pipeline
The NeMo Retriever team encourages enterprises to build their own agentic retrieval pipelines to meet their diverse needs. Try using a powerful commercial embedding model like llama-nemotron-embed-vl-1b-v2. Visit the NeMo Retriever library to explore tools and build a highly generalizable search workflow.
In-Depth Analysis and Implications
Array
Original source: Beyond Semantic Similarity: Introducing NVIDIA NeMo Retriever’s Generalizable Agentic Retrieval Pipeline