
 English
English  한국어
한국어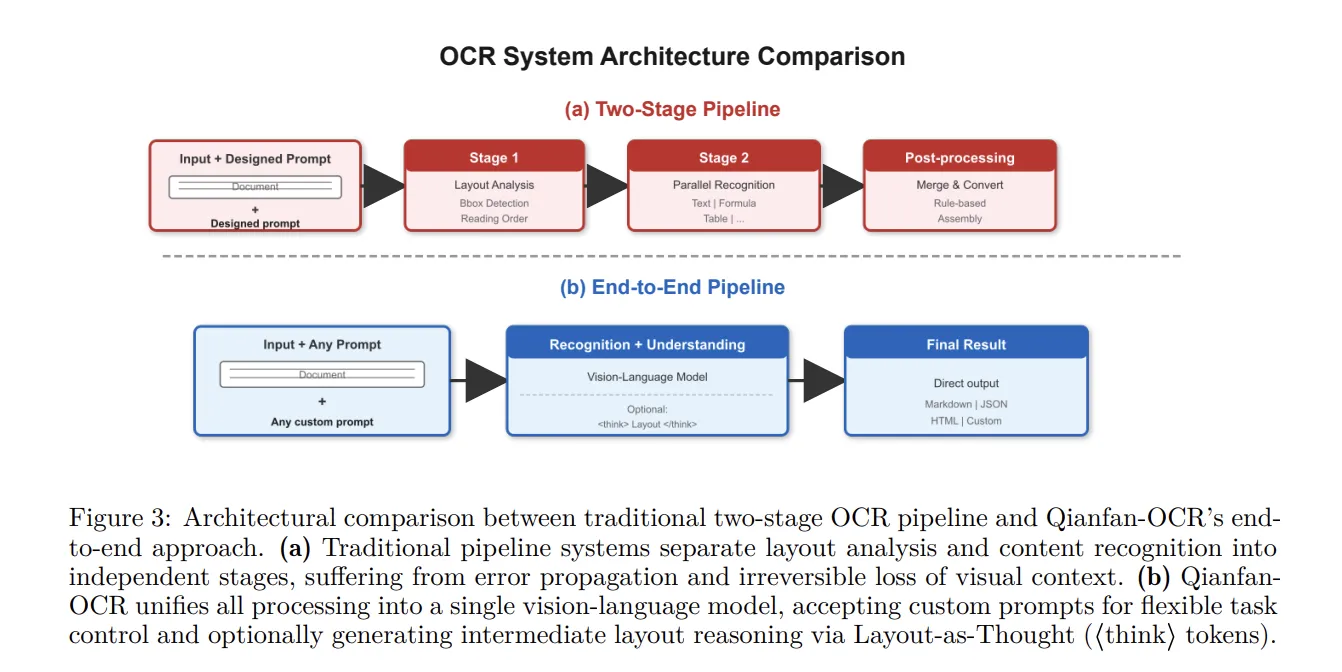
Baidu Qianfan Releases Qianfan-OCR: A 4B-Parameter Model Integrating Document Intelligence
Qianfan-OCR is not merely an advancement in OCR technology but a model with the potential to revolutionize the field of document intelligence. Traditional document processing methods required complex multi-stage pipelines, leading to high costs and low efficiency. Baidu aimed to overcome these limitations and has opened up new horizons in document processing with an integrated architecture.
Traditional OCR systems often processed layout detection, text recognition, and other steps separately. This resulted in bottlenecks due to dependencies between each step, slowing down the overall processing speed. Qianfan-OCR addresses this issue by integrating document parsing, layout analysis, and document understanding within a single vision-language architecture. This reduces complexity and contributes to maximizing efficiency compared to existing systems.
Core Technologies and Features of Qianfan-OCR
- Integrated Architecture: Qianfan-OCR maximizes processing efficiency by integrating document parsing, layout analysis, and document understanding into a single model.
- Layout-as-Thought Mechanism: Activated by a <think> token, this feature generates structured layout representations to improve document understanding, particularly effective for documents with mixed elements.
- Any Resolution Vision Encoder: Supports up to 4K resolution and generates up to 4,096 visual tokens to handle small fonts and dense text. This enhances the image processing capabilities of Qianfan-OCR.
- Grouped-Query Attention (GQA): Uses GQA to efficiently process a 32K context window, reducing KV cache memory usage by a factor of 4.
- AWQ Quantization: Achieves a 1.024 PPS inference efficiency through W8A8 AWQ quantization, showing a 2x speed improvement compared to W16A16.
Performance and Benchmarks
Qianfan-OCR has demonstrated excellent performance in various benchmark tests. It achieved a high score of 93.12 on the OmniDocBench v1.5, surpassing DeepSeek-OCR-v2 and Gemini-3 Pro. It also achieved high scores of 79.8 and 880 on the OlmOCR Bench and OCRBench, respectively, achieving the highest scores among end-to-end models and overall models. Notably, it achieved an average score of 87.9 on the Key Information Extraction (KIE) benchmark, exceeding the performance of much larger models. These results demonstrate that Qianfan-OCR goes beyond the limitations of existing OCR technology with innovative capabilities.
Industry Impact and Future Prospects
Qianfan-OCR’s emergence is a significant event that could transform the paradigm of document processing technology. Traditional OCR systems have been hampered by complex pipeline structures, resulting in slow processing speeds and difficulty handling various document formats. Qianfan-OCR offers the potential to address these issues and maximize the efficiency of document processing. It is expected to contribute to the construction of document automation and intelligent information retrieval systems in various fields such as law, finance, and healthcare in the future.
The integrated architecture of Qianfan-OCR is expected to have a significant impact on the future direction of artificial intelligence model development. The trend of moving away from the existing approach of separating steps and integrating various functions into a single model will accelerate. Furthermore, the outstanding performance demonstrated by Qianfan-OCR is expected to stimulate research and development investment in document intelligence technology and lead to new technological innovations. The successful development and release of Qianfan-OCR will further advance document processing technology and make our lives more convenient.
Technical Implications
- Importance of Multimodal Architecture: Qianfan-OCR demonstrates the effectiveness of a multimodal architecture integrating vision and language.
- Utility of Layout-as-Thought Mechanism: Utilizing layout information for document understanding contributes to improving the performance of end-to-end models.
- Importance of Quantization Technology for Efficient Inference: Technologies such as AWQ quantization are essential for increasing model efficiency and reducing deployment costs.
- Necessity of a GPU-Centric Architecture: CPU-based processing methods can cause bottlenecks, while a GPU-centric architecture increases the possibility of efficient bulk processing.
- Utilization of a 32K Context Window: A 32K context window helps understand the overall context of a document and derive more accurate results.
Deep Analysis and Implications
Array
Original Source: Baidu Qianfan Team Releases Qianfan-OCR: A 4B-Parameter Unified Document Intelligence Model


