한국어
한국어  English
English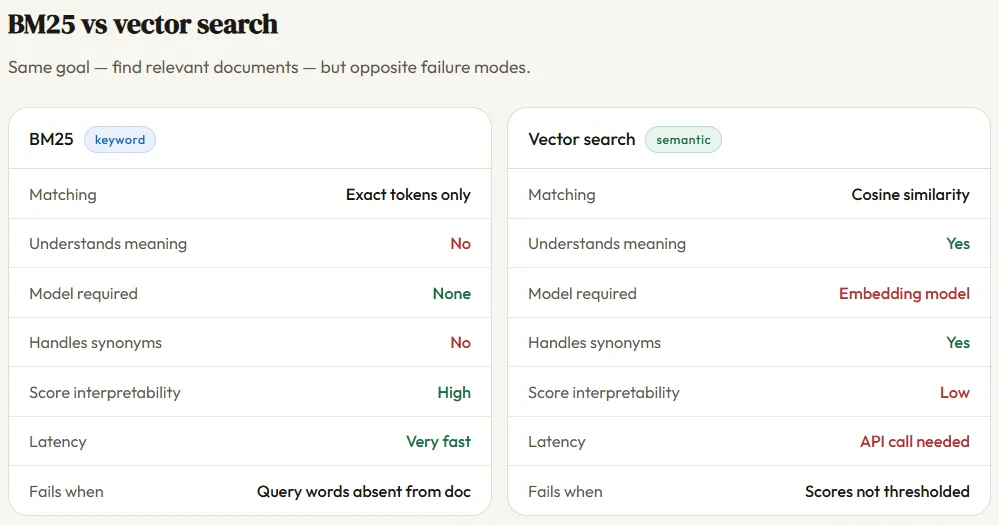
BM25와 RAG, 정보 검색 방식의 차이점은 무엇일까요?
정보 검색은 현대 디지털 시대에서 필수적인 기술입니다. 구글과 같은 검색 엔진은 사용자가 입력한 쿼리에 가장 적합한 문서를 찾아 순위를 매기기 위해 끊임없이 발전해 왔습니다. 이러한 과정에서 BM25(Best Matching 25)는 오랫동안 핵심적인 역할을 수행해 왔습니다. 하지만 BM25는 완벽하지 않으며, 최근에는 RAG(Retrieval-Augmented Generation)와 같은 새로운 접근 방식이 등장하며 정보 검색 패러다임에 변화를 주고 있습니다. 이번 글에서는 BM25와 RAG의 작동 원리를 비교하고, 각 방식이 가진 장단점을 살펴보고, 생산 시스템에서 어떻게 함께 활용될 수 있는지 자세히 알아보겠습니다.
과거에는 정보 검색이 단순히 키워드 일치 여부를 판단하는 것으로 충분했습니다. 하지만 사용자의 의도는 키워드보다 더 복잡할 수 있으며, 문맥과 의미를 고려하지 않은 검색은 정확한 결과를 제공하지 못할 수 있습니다. 이러한 문제점을 해결하기 위해 등장한 RAG는 BM25와 달리 의미 기반 검색을 가능하게 하며, 사용자의 의도를 더욱 정확하게 파악하여 관련 정보를 제공할 수 있습니다. BM25는 여전히 중요한 역할을 수행하지만, RAG와 함께 사용될 때 더욱 강력한 시너지 효과를 발휘할 수 있습니다.
BM25: 키워드 매칭의 고전
BM25는 Elasticsearch, Lucene과 같은 검색 엔진의 핵심 알고리즘입니다. BM25는 문서 내 키워드의 빈도, 키워드의 희귀성, 문서의 길이를 고려하여 문서의 관련성을 점수화합니다. BM25의 핵심적인 장점은 키워드 스터핑을 방지하는 능력입니다. 키워드를 20번 반복한다고 해서 문서의 관련성이 20배 증가하지 않도록, 빈도 포화라는 메커니즘을 적용하여 키워드 남용을 효과적으로 억제합니다. 하지만 BM25는 단어 기반 매칭 방식이므로, 정확한 키워드 일치에만 의존하여 검색하며, 사용자의 의도나 문맥을 이해하지 못한다는 한계점을 가지고 있습니다. 예를 들어, ‘심장마비’를 검색하면 ‘심부전’과 같은 의미적으로 유사한 문서를 찾지 못할 수 있습니다.
BM25의 작동 방식 상세 분석
- Term Frequency (TF): 문서 내 키워드 빈도를 측정합니다. 하지만 단순 빈도 계산 대신, 빈도 포화 메커니즘을 적용하여 빈도가 높아질수록 점수 증가폭을 감소시킵니다.
- Inverse Document Frequency (IDF): 키워드의 희귀성을 측정합니다. ‘the’와 같은 흔한 단어보다 ‘retrieval’과 같이 희귀한 단어에 더 높은 가중치를 부여합니다.
- Length Normalization: 문서의 길이를 보정합니다. 긴 문서는 키워드를 더 많이 포함할 가능성이 높으므로, 문서 길이에 따라 점수를 조정합니다.
RAG: 의미 기반 검색의 혁신
RAG는 BM25의 한계를 극복하기 위해 등장한 새로운 접근 방식입니다. RAG는 임베딩 모델을 사용하여 쿼리와 문서를 모두 벡터로 변환하고, 코사인 유사도를 계산하여 의미적으로 유사한 문서를 찾습니다. 이를 통해 BM25로는 찾을 수 없었던 유사한 의미의 문서를 검색할 수 있습니다. 예를 들어, ‘심장마비’를 검색하면 ‘심부전’과 같이 키워드는 다르지만 의미적으로 관련된 문서를 찾을 수 있습니다. 하지만 RAG는 임베딩 모델과 API 호출이 필요하므로, BM25보다 속도가 느리고 비용이 더 많이 듭니다.
RAG의 작동 방식 상세 분석
- Embedding Generation: 쿼리와 문서를 모두 임베딩 모델을 사용하여 벡터로 변환합니다.
- Cosine Similarity Calculation: 쿼리 벡터와 문서 벡터 간의 코사인 유사도를 계산합니다. 코사인 유사도는 0과 1 사이의 값을 가지며, 1에 가까울수록 의미적으로 유사합니다.
- Ranking: 코사인 유사도 점수를 기준으로 문서를 순위를 매깁니다.
BM25 vs. RAG: Python을 통한 비교 분석
BM25와 RAG의 차이점을 명확하게 이해하기 위해 Python 코드를 활용한 비교 분석을 진행했습니다. 먼저 필요한 라이브러리를 설치하고, 코퍼스를 정의하고, BM25 인덱스를 구축하고, 임베딩 리트리버를 구축합니다. 그 후 동일한 쿼리를 사용하여 BM25와 RAG를 실행하고 결과를 비교합니다. 이를 통해 BM25는 키워드 기반 검색에 강점을 보이는 반면, RAG는 의미 기반 검색에 강점을 보임을 확인할 수 있습니다. BM25는 빠르고 가볍지만, RAG는 더욱 정확한 검색 결과를 제공합니다. 따라서 두 기술을 함께 사용하는 하이브리드 검색이 최적의 솔루션입니다.
업계 영향 및 미래 전망
BM25와 RAG의 등장과 발전은 정보 검색 기술의 혁신을 가속화하고 있습니다. BM25는 여전히 많은 검색 엔진에서 널리 사용되고 있지만, RAG와 같은 새로운 기술의 도입으로 인해 그 역할은 점차 축소될 것으로 예상됩니다. 미래에는 BM25와 RAG를 결합한 하이브리드 검색이 더욱 보편화될 것이며, 사용자의 의도를 더욱 정확하게 파악하고 관련 정보를 제공할 수 있도록 지속적인 연구 개발이 이루어질 것입니다. 또한, 이러한 기술은 검색 엔진뿐만 아니라, 챗봇, 추천 시스템, 지식 관리 시스템 등 다양한 분야에 활용될 것으로 기대됩니다. BM25의 기본적인 원리를 이해하고 RAG의 장점을 활용하여 정보 검색 시스템을 개선하는 것은 앞으로의 중요한 과제가 될 것입니다.
결론적으로, BM25는 키워드 기반 검색의 강력한 도구이지만, RAG는 의미 기반 검색의 새로운 가능성을 제시합니다. 두 기술을 적절히 조합하여 사용함으로써, 정보 검색의 정확성과 효율성을 극대화할 수 있으며, 이는 다양한 산업 분야에 걸쳐 혁신을 가져올 것입니다. BM25와 RAG의 발전은 앞으로도 계속될 것이며, 우리는 이러한 변화에 발맞춰 새로운 기술을 배우고 적용해야 합니다.
심층 분석 및 시사점
Array