한국어
한국어  English
English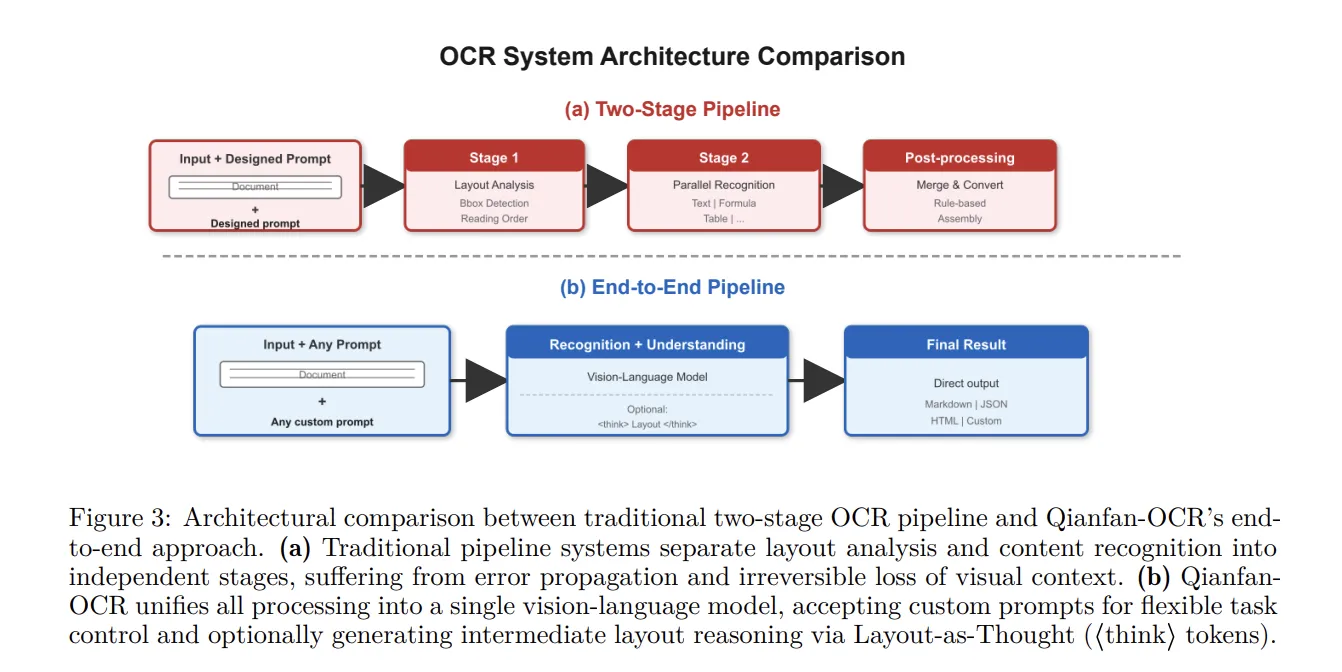
바이드우 첸판, 문서 지능을 통합하는 4B 파라미터 모델 첸판-OCR 출시
첸판-OCR은 단순히 OCR 기술의 진보를 넘어, 문서 지능 분야에 혁명적인 변화를 가져올 수 있는 잠재력을 지닌 모델입니다. 기존의 문서 처리 방식은 여러 단계의 복잡한 파이프라인을 거쳐야 했고, 이는 높은 비용과 낮은 효율성을 야기했습니다. 바이드우는 이러한 한계를 극복하고자 통합된 아키텍처를 통해 문서 처리의 새로운 지평을 열었습니다.
기존의 OCR 시스템들은 레이아웃 감지, 텍스트 인식 등 여러 단계를 분리하여 처리하는 경우가 많았습니다. 이는 각 단계 간의 의존성으로 인해 병목 현상이 발생하고, 전체적인 처리 속도가 느려지는 문제를 야기했습니다. 첸판-OCR은 이러한 문제를 해결하기 위해 단일 비전-언어 아키텍처 내에서 문서 파싱, 레이아웃 분석, 문서 이해를 통합했습니다. 이는 기존 시스템들이 겪었던 복잡성을 줄이고, 효율성을 극대화하는 데 기여합니다.
첸판-OCR의 핵심 기술 및 특징
- 통합 아키텍처: 첸판-OCR은 문서 파싱, 레이아웃 분석, 문서 이해를 하나의 모델로 통합하여 처리 효율성을 극대화합니다.
- Layout-as-Thought 메커니즘: <think> 토큰에 의해 활성화되는 이 기능은 구조화된 레이아웃 표현을 생성하여 문서 이해도를 향상시킵니다. 특히, 다양한 요소가 혼합된 문서에서 더욱 효과적입니다.
- Any Resolution Vision Encoder: 4K 해상도까지 지원하며, 작은 폰트와 밀집된 텍스트를 처리하기 위해 최대 4,096개의 시각적 토큰을 생성합니다. 이는 첸판-OCR의 이미지 처리 능력을 한층 더 끌어올리는 요소입니다.
- Grouped-Query Attention (GQA): 32K 컨텍스트 윈도우를 효율적으로 처리하기 위해 GQA를 사용하여 KV 캐시 메모리 사용량을 4배 줄입니다.
- AWQ Quantization: W8A8 AWQ 양자화를 통해 1.024 PPS의 추론 효율성을 달성하여 W16A16 기준 대비 2배의 속도 향상을 보여줍니다.
성능 및 벤치마크
첸판-OCR은 다양한 벤치마크 테스트에서 뛰어난 성능을 입증했습니다. OmniDocBench v1.5에서 93.12의 높은 점수를 기록하며 DeepSeek-OCR-v2 및 Gemini-3 Pro를 능가했습니다. 또한, OlmOCR Bench와 OCRBench에서도 각각 79.8과 880의 높은 점수를 기록하며, end-to-end 모델 및 전체 모델 중 최고 점수를 기록했습니다. 특히, 핵심 정보 추출(KIE) 벤치마크에서 87.9의 평균 점수를 기록하며, 훨씬 더 큰 모델들보다 높은 성능을 보여주었습니다. 이러한 결과는 첸판-OCR이 기존 OCR 기술의 한계를 뛰어넘는 혁신적인 모델임을 입증합니다.
업계 영향 및 미래 전망
첸판-OCR의 등장은 문서 처리 기술의 패러다임을 바꿀 수 있는 중요한 사건입니다. 기존의 OCR 시스템들은 복잡한 파이프라인 구조로 인해 처리 속도가 느리고, 다양한 문서 형식을 처리하는 데 어려움이 있었습니다. 첸판-OCR은 이러한 문제점을 해결하고, 문서 처리 기술의 효율성을 극대화할 수 있는 가능성을 제시합니다. 향후 법률, 금융, 의료 등 다양한 분야에서 문서 자동화 및 지능형 정보 검색 시스템 구축에 기여할 것으로 기대됩니다.
첸판-OCR의 통합 아키텍처는 향후 인공지능 모델 개발 방향에 중요한 영향을 미칠 것으로 예상됩니다. 여러 단계를 분리하여 처리하는 기존 방식에서 벗어나, 하나의 모델로 다양한 기능을 통합하는 추세가 가속화될 것입니다. 또한, 첸판-OCR이 보여준 뛰어난 성능은 향후 문서 지능 기술 발전에 대한 연구 개발 투자를 촉진하고, 새로운 기술 혁신을 이끌어낼 것으로 기대됩니다. 첸판-OCR의 성공적인 개발과 출시를 통해 문서 처리 기술은 더욱 발전하고, 우리의 삶을 더욱 편리하게 만들어 줄 것입니다.
기술적 시사점
- 멀티모달 아키텍처의 중요성: 첸판-OCR은 비전과 언어를 통합하는 멀티모달 아키텍처의 효과를 입증합니다.
- Layout-as-Thought 메커니즘의 효용성: 문서 이해를 위한 레이아웃 정보를 활용하는 방식은 end-to-end 모델의 성능을 향상시키는 데 기여합니다.
- 효율적인 추론을 위한 양자화 기술의 중요성: AWQ 양자화와 같은 기술은 모델의 효율성을 높이고 배포 비용을 절감하는 데 필수적입니다.
- GPU 중심의 아키텍처의 필요성: CPU 기반의 처리 방식은 병목 현상을 유발할 수 있으며, GPU 중심의 아키텍처는 효율적인 대량 처리 가능성을 높입니다.
- 32K 컨텍스트 윈도우의 활용: 32K 컨텍스트 윈도우는 문서 전체의 맥락을 파악하고, 더욱 정확한 결과를 도출하는 데 도움이 됩니다.
심층 분석 및 시사점
Array
원문 출처: Baidu Qianfan Team Releases Qianfan-OCR: A 4B-Parameter Unified Document Intelligence Model